
Due before 10pm, Sunday, Sunday 06, 2016
In this lab you will implement a doubly linked list and perform some timing experiments on it.
The purpose of this lab is to:If you'd like, you may work with one partner on this lab. If you choose to do so, you must both contribute equally to the work of this lab, and are both responsible for understanding its workings. You can then hand in one submission between the two of you, with both your names clearly marked somewhere obvious to the graders (e.g., README and headers of all files).
Your first task is to implement a doubly linked list called MyLinkedList<T> and a corresponding ListIterator for your class.
I have some starting point code for you here: lab4.zip Create a Lab 4 folder and unzip this file into it before you create your Lab4 project in Eclipse.
In this lab you create a class called MyLinkedList<T>. Your class is just a subset of LinkedList, and therefore should match its behavior on this subset.
Your class should extend AbstractList<T> and later in this lab you will create a ListIterator (either as a nested class or as an anonymous class).
When you have finished your implementation, be sure to test it thoroughly before continuing. In doubly linked lists, the removal of items can be especially tricky as you need to be sure to properly update all of the pointers of the next and previous elements, as well as handle the special cases for removal from the front or tail. Keep a piece of paper with you and draw pictures to help with your coding. Nobody writes this code without referring to pictures.
You should not allow "null" values to be inserted into the list; if the user of your class attempts to do so, you should throw a NullPointerException.
You should only need to have a single public 0-argument constructor that creates an empty list and initializes all the necessary variables.
I also had a removeNode(Node n) method that allowed me to not have to duplicate code in my iterator. But you aren't required to implement one unless you want to.
public class MyLinkedList<T> extends AbstractList<T> {
class Node {
T data;
Node next;
Node prev;
// more code here
}
/* Lots more code will go here */
}
You should be able to re-use the tests you wrote in Lab 2 for MyArrayList. Copy the MyArrayListTest.java file into your lab4 folder and rename it to be MyLinkedListTest.java. Or just have eclipse create the JUnit source file MyLinkedListTest.java and copy and paste from your MyArrayListTest.java file. Then you can open up the file, rename the public class to be "MyLinkedListTest", and then update the methods to use LinkedLists instead of ArrayLists. Just change MyArrayList and ArrayList to MyLinkedList and LinkedList throughout so you get lines like
MyLinkedList<String> x = new MyLinkedList<String>();
Once your MyLinkedList class is working, you will need to create a ListIterator which is returned by the factory listIterator() method. You can do this one of two ways:
public ListIterator<T> listIterator(){
return new ListIterator<T>(){
// TODO - your code here
};
}
class MyLinkedListIterator implements ListIterator<T> {
// class variables here
public boolean hasNext() {
// your code here
}
// more methods, etc.
}
The text talks about nested classes on p. 96. If you want more, here is Oracle's discussion of nested classes. You can read about anonymous classes here. Most people new to Java, and even some experienced ones, find nested classes easier to handle than anonymous classes, but you are free to use either technique.
The ListIterator is able to traverse the list by moving a space at a time
in either direction. It might be helpful to consider that the iterator has
size+1 positions in the list: just before the head, between the 0 and 1
index, ..., just after the tail.
After one call to next(), the iterator is logically in the state shown below (click to enlarge).
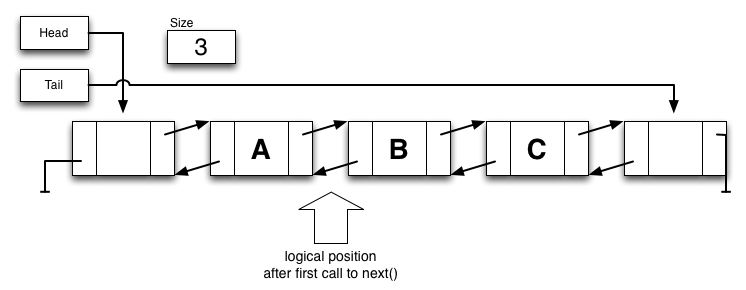
In either case, you will need to implement all of the methods of a listIterator -- hasNext()/next(), hasPrevious()/previous(), nextIndex()/previousIndex(), remove(), set(x), and add(x). See the JavaDoc for details, but I do have some notes below.
You will need to implement all of the following methods. See ListIterator for details.
I found that it was useful to have a number of state fields to simplify the writing of the various methods above. Since the cursor of the ListIterator exists logically between 2 nodes, I found it was useful to just keep references to the next Node and the previous Node. I also kept an int value of the index of the next node.
If you construct your MyLinkedList to use sentinel nodes as discussed in the book and lecture, and you properly throw exceptions for going out of range, you shouldn't have to worry about checking for null values at the ends of the list since the sentinel nodes are there.
Since set() and remove() both change based on what direction we were last traversing, I kept a boolean flag to tell me if I was last going backwards.
It is possible, and sometimes useful, to have several iterators working on the same list. If they both try to change the structure of the list you could get into an unpredictable state. Therefore you should check that the list hasn't been modified by someone else before you let an iterator make a modification. An easy way to do this is to have both the list and the iterator keep track of the number of modifications that have been made to the list. When the iterator is created it grabs the list's modification count. Each change the iterator makes to the list increases both its and the lists modification count. However, if you have two iterators modifying the list, one of them will find that its modification count will be different from the list's, so you will know that the list structure has been changed and that iterator is no longer viable. See modCount and the text for additional details and suggestions.
Once you are sure your iterator is working, you should override the following methods in MyLinkedList. Each of these should just create a new MyLinkedListIterator and return it.
Note: You inherit a working ListIterator from
AbstractList, but the one you create will be more efficient. I suggest
that while you are building and initially testing your ListIterator, you
create a differently named factory method to use. I tend to use names
like QQQiterator() and QQQlistIterator() until I'm sure
it is working correctly. If you jump right into overriding
iterator()/listIterator() then things like
toString() may stop working for you.
Be sure to have it called just iterator() and listIterator() in your submitted MyLinkedList and JUnit code.
Many students last semester just left it as 'QQQiterator' which broke things, and made the graders think you had skipped that step.
You'll want to test your ListIterator and be sure that it works properly. One good way to test this would be to create a JUnit test in MyLinkedListTest.java that will perform the Sieve of Eratosthenes. In case you've not encountered this before, the "sieve" is used to determine prime numbers. The basic idea is that you initially list all of the integers in the range as potential prime numbers, then go through the possible factors one-by-one (starting from 2) and cross out any value on your list that is a multiple of it (but not the number itself).
So assuming you have the numbers from 2-10, you'd first go through and cross out the multiples of 2 other than itself (4,6,8,10) and then multiples of 3 other than itself (9, since the 6 is already gone), etc. You should stop when you reach the square root of the larger range end. What you're left with should be all the primes in the given range.
For example, the Sieve of [11,20] would return 11, 13, 17, and 19, and the Sieve of [1,20] would return 2, 3, 5, 7, 11, 13, 17, and 19.
Note that the sieve is not a required part of this lab; it is just a suggestion for an interesting test case.
Now that you are sure that you have a working MyLinkedList and a working iterator, let's create a variation of the list. You will be creating a Most Recently Used (MRU) List which is derived from your existing list. The idea behind a MRU list is that when an item is looked up in a list, it is often looked up again in the near future. To try and improve lookup times, whenever an item is "found" in the list, it is moved to the front of the list so that subsequent searches for it might be faster.
Create a class MRUList<T> that extends your MyLinkedList<T>. You will need to override a few inherited methods.
super.add(0,x) calls the parent class' method.
remove(index) and then adding back to the front.
Also create JUnit test cases for your MRUList in a file called MRUListTest.java.
If you are having trouble getting your MRU class working correctly, try
extending java.util.LinkedList<T> instead of
MyLinkedList and see if it is a problem in your logic or in
your MyLinkedList class.
For this next part, I want you to use a provided class called CollectionTimer that will let you compare the running time of using your MyLinkedList and MRUList to do a spell checking task.
What the CollectionTimer does is read in a list of known "good" words which it stores in a collection such as your MyLinkedList. It then reads a fixed number of words from a second file and checks to see if they are contained in the "good" list or not. The program will keep track of the number of words that matched or not, but that isn't displayed unless you enable debugging information in the CollectionTimer. Instead, it keeps track of the number of milliseconds that have elapsed during the performance of this task. It only starts timing once it is doing the word list lookup, so setup time is not included.
The program takes 6 arguments as described below. The first 2 are required. The other 4 are optional and are used to change the amount of work performed for each iteration.
Here is the output on my laptop using the default number of words, increments, and steps.
% java CollectionTimer medium-wordlist.txt pride-and-prejudice.txt
Wordlist: medium-wordlist.txt Document: pride-and-prejudice.txt
words: 5000 increment: 5000 steps: 5 reps: 5
Class: MyLinkedList
=======================================
1: 5000 words in 2473 milliseconds
2: 10000 words in 4848 milliseconds
3: 15000 words in 7489 milliseconds
4: 20000 words in 9731 milliseconds
5: 25000 words in 12182 milliseconds
Wordlist: medium-wordlist.txt Document: pride-and-prejudice.txt
words: 5000 increment: 5000 steps: 5 reps: 5
Class: MRUList
=======================================
1: 5000 words in 908 milliseconds
2: 10000 words in 1525 milliseconds
3: 15000 words in 2092 milliseconds
4: 20000 words in 2684 milliseconds
5: 25000 words in 3310 milliseconds
I've included a number of wordlists for you to try comparing against. I also included a copy of "Pride and Prejudice" from Project Gutenberg which has 121557 words which should contain more than enough text for you to test against for your loops. The wordlist files have the following word counts:
You should not need to make any modifications to CollectionTimer. There is a debug flag that you can enable to let you see some of the inner workings. This might be useful if you think that your MyLinkedList or MRUList might be losing items or not working correctly.
Copy and paste the output from one run of CollectionTimer using small-wordlist.txt and pride-and-prejudice.txt with default for the rest. I.e., the command I used just above.
If you find that it is running too quickly/slowly, you may need to modify things from the default parameters. If you do so, be sure to document what settings you are using in your README. Try and have the number of lookups double, and then double again, to get a good range of observations.
The running time for this task should be linear in terms of the number of items in our wordlist. (To determine a "miss" you would need to look at every word in the list.) Let's call this n. It is also linear in terms of the number of words to be read in. Let's call this m. Taken together, you might express this as O(m n).
Looking at the table you've generated, as the size of m doubles, you would expect the worst case running time to also double. Does this hold for your observations? Be sure to consider MyLinkedList and MRUList separately. Why do you think this is?
Now re-run your experiment from Question 1, but this time using the medium-wordlist.txt. Include this table in your README.
This wordlist is 9 times the size of small-wordlist.txt. How does this change the performance of each type of list? Why do you think this is?
Note: if this is running too slowly for you, you can run it for values "500 500 5 5", but include the chart for both small and medium.
Now re-run your experiment but use pride-and-prejudice.txt as both the wordlist and the document to be checked. Include this table in your README. What do you observe about the running times now? Why do you think this is?
Look through your programs and make sure you've included your name at the top of all of them.
Include in your submission a file named README. The contents of the README file should include the following:
Look through your programs and make sure you've included your name at the top of all of them.
We are expecting you to hand in at least the following files:
If you adhered to the honor code in this assignment, add the following statement to your README file:
I have adhered to the Honor Code in this assignment.
You now just need to electronically handin all your files. Assignment is 4.
Don't forget to run lshand and verify that things were submitted.
