CSCI 150: Lab 5
Strings and Lists
Due: 10PM on Tuesday March 19
The purpose of this lab is to:
- Practice using strings, lists, and files
- Play a game!
- Explore two connections between computer science and biology
- Encounter machine learning
Before you begin, please create a folder called lab05 inside your cs150 folder. This is where you should put all files made for this lab.
Part 1 - Mind Mastery
game.py: 14 points, individual.
Mastermind is a neat (although oftentimes frustrating) puzzle game. It works a something like this: There are two players. One player is the codemaker (your program), the other is the codebreaker (the user). The codemaker chooses a sequence of four colored pegs, out of a possible six colors (red, blue, green, yellow, orange, and purple). They may repeat colors and place them in any order they wish. This sequence is hidden from the codebreaker. The codebreaker has 10 chances to guess the sequence. The codebreaker places colored pegs down to indicate each of their guesses. After each guess, the codemaker is required to reveal certain information about how close the guess was to the actual hidden sequence.
Describe the Problem: |
In this part of the lab, you will create a program to play Mastermind, where computer is playing the codemaker, and the human user is the codebreaker. Thus your program needs to generate a secret code, and repeatedly prompt the user for guesses. For each guess, your program needs to give appropriate feedback (more detail below). The game ends when either the user guesses correctly (wins) or uses up 10 guesses (loses). | |||||||||||||||||||||
Understand the Problem: |
The trickiest part of this game is determining how to provide feedback on the codebreaker's guesses. In particular, next to each guess that the codebreaker makes, the codemaker places up to four clue pegs. Each clue peg is either black or white. Each black peg indicates a correct color in a correct spot. Each white peg indicates a correct color in an incorrect spot. No indication is given as to which clue corresponds to which guess.
For example, suppose that the code is RYGY (red yellow green yellow). Then the guess GRGY (green red green yellow) would cause the codemaker to put down 2 black pegs (since guesses 3 and 4 were correct) and 1 white peg (since the red guess was correct, but out of place). Note that no peg was given for guess 1 even though there was a green in the code; this is because that green had already been "counted" (a black peg had been given for that one). As another example, again using RYGY as our code, the guess YBBB would generate 1 white peg and 0 black; yellow appears twice in the code, but the guess only contains one yellow peg. Likewise, for the guess BRRR, only 1 white peg is given; there is an R in the code, but only one. Below is a table with guesses and the correponding number of black and white pegs given for that guess (still assuming the code is RYGY).
A sample run of our text-based program may look like this: Sample output
%python3 game.py
I have a 4 letter code, made from 6 colours.
The colours are R, G, B, Y, P, or O.
Your guess: GGGG
Not quite. You get 0 black pegs, 0 white pegs.
Your guess: YYYY
Not quite. You get 1 black pegs, 0 white pegs.
Your guess: YOYO
Not quite. You get 0 black pegs, 2 white pegs.
Your guess: PPYO
Not quite. You get 1 black pegs, 2 white pegs.
Your guess: POYB
Not quite. You get 1 black pegs, 3 white pegs.
Your guess: PBOY
You win! So clever.
|
|||||||||||||||||||||
Design an Algorithm |
Once you understand how the game works, you should design a pseudocode plan of attack. The general steps are:
|
|||||||||||||||||||||
Implement a Design |
Now that you have some of the kinks worked out in theory, it is time to write your program game.py.
You may assume the user always provides a guess with the available colors, and always in uppercase. Make and use an integer constant NUM_TURNS that represents the number of allowable turns (say, 10). generateCode()To generate the code, write a method generateCode() that generates the codemaker's code (and returns it as a String to the caller). That is, this method should randomly generate 4 colored pegs, selected from R, B, G, Y, O, and P, and return it as a 4-letter string. You'll want to use the random methods as discussed in lab03 in order to randomly generate a color for each peg. In particular, you'll generate an integer between 0 and 5 inclusive, and use if-statements to map each result to one of the 6 colors (if the random number is a 0, add a "R" to the code; if the random number is a 1, add a "B" to the code; etc.). Test your generateCode() method thoroughly before continuing. No, seriously, test it before continuing.clue(code, guess)Next, write a method clue(code, guess) that prints out the white and black clue pegs according to the given guess and code, and returns True if code equals guess, and False otherwise. Translate the pseudocode above to help you out.Note that you can "change" the i-th character in a string s to an 'x' as follows: |
|||||||||||||||||||||
Test the Program |
It is hard to test your program when you are given a random code that you don't know. Therefore, you should print out a hint message at the beginning of the program with the actual code, so that the graders know what the correct answer is when evaluating the number of black and white pegs your program provides. |
Part 2 - Guess that Flower!
predict.py: 12 points, partner allowed.
Files Needed: (download each to your lab05 folder)
- predict.py
- predict_helpers.py
- iris_measurements.csv
- iris_species.csv
- iris_measurements_unknown.csv
- iris_species_unknown.csv

In many areas of life, we can make accurate predictions about something we do not know by using information we have already seen or learned. In computer science, we call this process supervised machine learning, where a computer learns how to make predictions using only previously seen examples (without explicit programming using conditionals or rules for how to make predictions).
One of the first classic examples (studied by Ronald Fisher in 1936) of using machine learning to make predictions is in guessing the species of a flower given only measurements about the length and width of its petals and sepals. In this lab, we will complete a program that performs machine learning using an algorithm called k-nearest neighbor.
k-Nearest Neighbor
The k-Nearest Neighbor algorithm works something like this. Say you have a data point consisting of multiple measurements (e.g., flower size, ingredient amounts, pixel colors) that you want to make a prediction about (e.g., flower species, recipe type, what type of animal is in the picture). We can compare that data point against others for which we know their type or category (e.g., iris versicolor, brownies, cat photo) and then use the type or category of the closest matching data point(s) as our prediction.
Describe the Problem: |
Complete the already started program predict.py that makes predictions about the species of flowers based on their measurements using comparisons to other flowers for which we know their species. |
Understand the Problem: |
We can represent each flower as a list of four measurements: sepal length, sepal width, petal length, and petal width.
Thus, one flower might be represented as a list: The program predict.py already provides a main function for you that reads in all of the flowers from the CSV files mentioned above. Specifically, it creates three lists for you:
|
Design an Algorithm: |
To calculate the distance between any two flowers based on their measurements, we an reuse the Euclidian distance formula we used in Lab 03 for the Monte Carlo pi approximation program. If two data points (call them x and y) have four measurements, their Euclidian distance is:
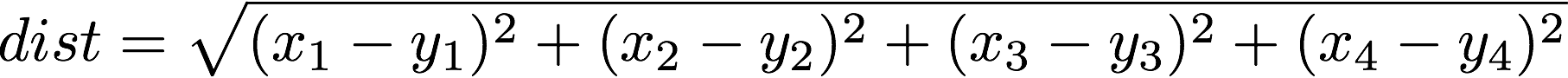
|
Implement a Design |
You will implement your solution by adding code to the predict.py program. You will also need to download the predict_helpers.py module into the same directory (which includes some predefined functions that you will need, e.g., for reading data from file and for calculating the accuracy of your predictions). |
Test the Program: |
Run your program. If correctly implemented, you should achieve very high accuracy (not quite 100%, but close!). Of note -- such high accuracy is actually pretty remarkable. The entire data set contains equal numbers of the three species of iris flowers. So random guessing (assuming the program learns nothing) would only achieve 33% accuracy! The fact that we achieve much better results demonstrates the potential power of machine learning, especially as applied to other disciplines (such as biology). |
Maintain: |
Make sure your code is "readable": use short but meaningful variable names and make sure to add your own comments explaining what you are doing. |
Handin |
Be sure to hand in what you have finished so far. |
Part 3 - Looking for a Match
match.py: 20 points, partner allowed.
Files Needed: (download each to your lab05 folder)
As you may know, proteins are chains of molecules called amino acids. There are 20 amino acids, each of which is typically represented by a single letter, and any protein can be specified by its sequence of amino acids. This sequence determines the properties of the protein, including its 3D structure.
Right: 3D structure of a protein. Image source: wikipedia.org.
When a new protein is found, one way in which we might attempt to guess the functionality of that protein would be to see if it contains certain markers common to a known class of proteins. For example (and an entirely bogus example at that), suppose we discover a new protein, that we've named Duane, with the following amino acid sequence:
STTECQLKDNRAWTSLFIHTGHTECA
We may also suspect that Duane might belong to one of two possible classes of proteins: Spiffs and Blorts. As you well know, most Spiffs contain the pattern TECQRKMN or at least something close to it. That is, most of the sequences in the class of Spiff proteins have the subsequence TECQRKMN with only a few of the letters changed. Blorts, meanwhile, have the pattern ALFHHTTGT, or something very similar.
In this case, we can deduce that Duane is most likely a Spiff: Duane contains the pattern TECQLKDN which only has 2 mismatches from TECQRKMN (the errors are marked with a ^ below).
TECQLKDN
TECQRKMN
^ ^
The closest pattern to the Blort sequence is
SLFIHTGHT
ALFHHTTGT
^ ^ ^^
which has 4 mismatches.
Describe the Problem: |
Input: A file that contains a string s representing a protein sequence, along with some number of strings, each representing a marker sequence.
Goal: For each marker sequence, find its best match in the protein sequence and report its location and the number of errors in the match. |
Understand the Problem: |
The file test.txt is in the format you should expect for your input (and is the file you should use to test your program). In particular, the first line will always contain the protein sequence. Following the protein sequence will be some number of pattern sequences. For each of these sequences, you should report the location of the best match, and the number of errors at that location.
For example, the contents of test.txt are as follows:
STTECQLKDNRAWTSLFIHTGHTECA
TECQRKMN
ALFHHTTGT
TTECQ
HT
ZZZ
TTZZZRAWT
For this file your program should have something like the following output:
Example Output
Sequence 1 has 2 errors at position 2.
Sequence 2 has 4 errors at position 14.
Sequence 3 has 0 errors at position 1.
Sequence 4 has 0 errors at position 18.
Sequence 5 has 3 errors at position 0.
Sequence 6 has 5 errors at position 5.
|
Design an Algorithm: |
Make sure you come up with a plan of attack (on paper) before you begin coding. |
Implement a Design: |
Unlike previous assignments in which data was entered by the user or hard-coded into the program, here your data will come from a file. As such, you'll need a few tools for handling files.
Reading from a FileTo work with an external file, you'll use the open function:
Keep in mind that the lines returned by all these functions include the newline character at the end of each line. So if you call the print function on one of these lines, you'll print two newlines (creating a blank line). If you want to avoid this, you can either tell print not to add a newline at the end (end='') or you can just work with all but the last character in the line (myLine[:-1]). You can also use a for loop to iterate through all the remaining lines in the file. For example, |
Test the Program: |
Try your program on a variety of sequences and inputs. Make sure the program still works when the protein sequence or some pattern sequence is empty. |
Maintain: |
Make sure your code is "readable": use short but meaningful variable names, use constants where appropriate, use functions where you can, and comment any code that does anything substantial (for example, it would be a good idea to put a comment before your for loops explaining the purpose of the for loops, before each function explaining the function's parameters and purpose, etc.) It is not necessary to comment assignment statements and simple things like that.
You should also handle exceptions so as to make your program robust to runtime errors (e.g. the user if enters a file name that doesn't exist). |
Handin |
Be sure to hand in what you have finished so far. |
Part 4 - Wrap Up
As with every lab, your last job prior to submission is to complete a brief write-up by filling out a Google Form.
Handin
You now just need to electronically handin all your files. As a reminder
% cd # changes to your home directory % cd cs150 # goes to your cs150 folder % handin # starts the handin program # class is 150 # assignment is 5 # file/directory is lab05 % lshand # should show that you've handed in something
You can also specify the options to handin from the command line
% cd ~/cs150 # goes to your cs150 folder % handin -c 150 -a 5 lab05
File Checklist
You should have submitted the following files:
game.py
predict.py
match.py
predict_helpers.py (for ease of grading)
iris_measurements.csv (for ease of grading)
iris_species.csv (for ease of grading)
iris_measurements_unknown.csv (for ease of grading)
iris_species_unknown.csv (for ease of grading)
test.txt (for ease of grading)
A. Eck, T. Wexler, A. Sharp.